
WHAT ARE LLM PARAMETERS AND WHY ARE THEY IMPORTANT?
LLM parameters are the building blocks of large-language models. They represent weights and biases that determine how input data is processed. Each parameter fine-tunes the model's ability to predict, generate, or interpret text. In essence, understanding these parameters helps us harness their power effectively. If you are developing apps or studying AI, you must know their significance. It is key to navigating this fast-evolving field.
UNDERSTANDING THE ROLE OF PARAMETERS IN LARGE LANGUAGE MODELS
Parameters serve as the backbone of large-language models in generative AI. They are the adjustable elements that define how these models understand. Each parameter captures patterns from the learning data, enabling generative AI model to produce coherent and contextually relevant outputs.
They adjust their parameters based on learned relationships in the data. This learning affects both output quality and adaptability to different apps. A mix of billion parameters and context turns raw text into coherent stories or answers. They are tailored for specific needs.
HOW PARAMETERS INFLUENCE AN LLM'S PERFORMANCE AND CAPABILITIES
Parameters serve as the backbone of large-language models. They determine how well a model understands and generates text. Each parameter is a learned weight. It adjusts during training, which can make these models expensive to train. This affects the connections between parts of the neural network.
A model ability to capture language's nuances often relates to its number of parameters. More parameters can improve an LLM's understanding and output. It can then generate more coherent, relevant responses.
THE RELATIONSHIP BETWEEN PARAMETERS AND COMPUTATIONAL RESOURCES
It's vital to understand large-language models. This is due to the link between their parameters and the resources needed to run them. Each parameter in an LLM requires memory and processing power to function effectively. As the number of parameters grows, so does the need for strong computing power. This can range from powerful GPUs to extensive cloud computing setups.
More parameters often correlate with improved capabilities but at a cost. Striking a balance becomes essential. Developers must consider not just model performance, but also hardware and energy use. Efficient resource use can make or break a project, especially when scaling up.
Improving algorithms helps mitigate some of these constraints. Techniques like pruning or quantization help developers. They reduce resource use but keep effectiveness. This adaptability allows smaller organizations to use advanced AI at low cost.
HOW DOES THE NUMBER OF PARAMETERS AFFECT AN LLM'S PERFORMANCE?
A LLM performance relies on its parameters. More parameters of the model usually improve a model's abilities. It can then capture subtle patterns in language data. As LLMs grow, they can better understand context. They can then generate more coherent responses. This enhanced understanding is crucial for tasks like translation, summarization, and conversation generation.
EXPLORING THE IMPACT OF MODEL SIZE ON LANGUAGE GENERATION
Model scales significantly influence language-generation capabilities. Larger models, with millions or even billions of parameters, often understand context and nuance better. They can generate text that feels more coherent and human-like.
Developers must consider the trade-off between performance and resource use. They want to use these powerful tools effectively, ensuring that phrases in the training data are accurately represented. Balancing these aspects leads to exciting possibilities in natural language understanding and generation.
BALANCING MODEL SIZE AND EFFICIENCY: WHEN DO MORE PARAMETERS HELP?
It is vital to balance model scales and efficiency in developing large-language models. More parameters often lead to better performance. But, it's not guaranteed. In some cases, increasing parameter count enhances understanding of complex contexts.
- Increased Computational Costs and Longer Processing Times: Scaling up models often leads to higher computational requirements and longer processing times.
- Choosing When to Scale Up: Deciding to scale up involves evaluating the complexity of the task against the available infrastructure.
- Experiments Showing Compact Models Can Outperform Larger Ones: In some cases, compact models have been observed to outperform larger ones.
- Reasons for Smaller Models Outperforming Larger Ones: This can be attributed to:
- Better training methods.
- The use of curated data sets.
Efficiency doesn't just depend on size. It hinges on how well parameters are used in each unique application.
THE TRADE-OFFS BETWEEN LARGER MODELS AND COMPUTATIONAL REQUIREMENTS
Larger-language models promise impressive capabilities. They come with significant computational demands. Increased parameters must more memory and processing power. Running these extensive models can strain available resources. This means longer training times and higher operational costs. For businesses and developers, this poses tough decisions about budget and infrastructure.
| Aspect | Larger-Scale Models | Computational Requirements |
|---|---|---|
| Performance | Potentially higher accuracy and capability | Requires more resources to achieve |
| Training Time | Longer training times | Increases significantly with model scale |
| Inference Speed | Slower inference | Higher latency for predictions |
| Hardware Needs | Requires powerful GPUs/TPUs | Expensive infrastructure investments |
| Energy Consumption | Higher energy usage | Increased operational costs |
| Scalability | Challenging to scale efficiently | Limited by available computational power |
| Cost | Higher upfront and maintenance costs | Budget constraints may limit feasibility |
Bigger models may lead to diminishing returns in performance. The benefits of adding more parameters may not be worth the cost and complexity. Balancing size against efficiency becomes crucial for practical applications. Little models can often deliver satisfactory results while being easier to manage. In AI projects, choosing between model scales and resources is key to success. Adapting strategies to specific needs ensures tech is used well, with no extra burden.
WHAT IS THE SIGNIFICANCE OF TRAINING DATA IN LLM PARAMETERS?
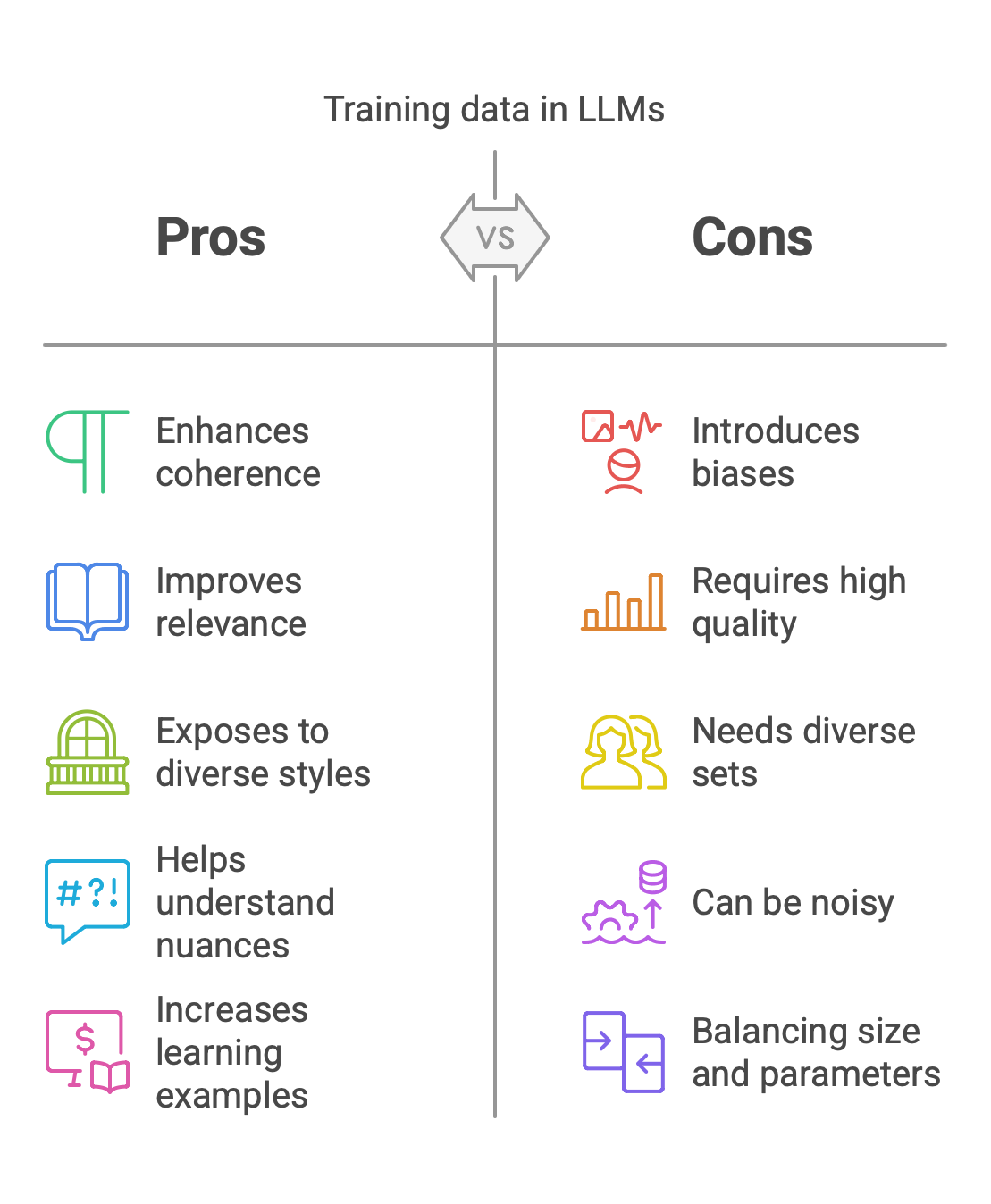
Training-data serves as the backbone of large-language models. An LLM's ability to generate coherent, relevant text depends on the quality and diversity of its training-data. When training a model, it's not just about quantity; its also about variety. Diverse data sets expose the model to different writing styles, vocabularies, and contexts. This breadth helps the LLM understand nuances in language more effectively.
Biases present in the training-data can seep into model behavior. If some views are underrepresented or misrepresented, the content may be flawed. Improving data set quality is crucial for better outcomes in performance and reliability. This balance of size and richness is key. It shapes an effective LLM that meets user expectations in various apps, including the best LLM for coding, which requires precise, unbiased, and contextually accurate outputs to assist developers effectively.
HOW TRAINING DATA INFLUENCES PARAMETER LEARNING AND MODEL PERFORMANCE
Training-data is the backbone of any large-language model. It dictates how effectively parameters learn patterns and relationships in language. Conversely, poor or biased training-data can lead to skewed results. If a data set lacks diversity, the model could struggle with some topics and groups. As a result, its performance diminishes when faced with real-world scenarios. The quantity of training-data matters too.
More examples usually improve learning. But, they must be relevant and well-organized. Noise in the data set can confuse parameter adjustments during training. Successful parameter learning relies on the quality and variety of training-data. It shapes what models know and how well they apply that knowledge across complex tasks.
OPTIMIZING DATASET QUALITY AND DIVERSITY FOR BETTER LLM RESULTS
Data set quality and diversity are crucial for training effective large-language models. High-quality data ensures the model learns from correct information. Diverse data sets expose it to various styles, cultures, and contexts. When curating a data set, it's essential to include many genres and topics. This approach helps the LLM understand nuanced language patterns.
A narrow data set may limit its adaptability in real-world applications. Incorporating user feedback during training can further enhance results. Developers can improve their models by learning how people interact with generated text. Improving both quality and diversity pays off in LLM performance.
BALANCING DATASET SIZE WITH MODEL PARAMETERS FOR OPTIMAL OUTCOMES
The relationship between data set size and model parameters is a delicate dance. A larger data set can help the model learn complex patterns. It will provide more context for it. If the model parameters don't match the data, inefficiencies can arise. Improving both dimensions requires careful consideration of specific tasks and goals.
Testing various combinations helps identify what works best in practice. This approach often finds surprises in how models behave with different inputs and settings. Balancing these elements ensures better performance while maintaining efficiency across applications.
HOW DOES THE TEMPERATURE PARAMETER AFFECT LLM OUTPUT?
Llm temperature parameter is key to the output of large-language models. It essentially controls randomness during text generation. A lower temperature value, say around 0.2, produces more deterministic outputs. This means the model is likely to choose words and phrases that it deems most relevant based on its training-data. The result? Responses that are coherent and focused but may lack creativity.
UNDERSTANDING THE TEMPERATURE VALUE IN LANGUAGE GENERATION
The temperature control is a fascinating aspect of natural language generation. It directly influences the randomness of predictions made by large-language models. A lower-temperature value, for instance, leads to more deterministic outputs. This means the model sticks closely to common patterns and structures in language.
- Introducing Variability with Higher-Temperature: Increasing the temperature introduces more variability in the output.
- Effects of Higher-Temperature:
- Output becomes more creative and diverse.
- However, it may also become nonsensical.
- Balancing Act: It's a trade-off between coherence and imagination.
- Choosing the Right Temperature:
- For tasks requiring precision (e.g., summarizing, translating), a lower-temperature is often better.
- For creative tasks (e.g., creative writing), a higher temperature value can spark creativity.
Experimenting with different temperatures helps users get better responses. It shows how flexible LLMs are at understanding context and intent.
EXPLORING THE EFFECTS OF HIGHER AND LOWER TEMPERATURE SETTINGS
Temperature settings are key. They shape the output of large-language models. They determine how creative or conservative the generated text will be. With a higher temperature, say around 1.0 or above, the model becomes more adventurous. It introduces unexpected terms and phrases, often leading to playful and imaginative responses. It can help in brainstorming or writing poetry where creativity is key.
On the flip side, lower temperaturesaround 0.2 to 0.5create more predictable outputs. The model prefers common phrases and safer word choices. So, it's best for tasks needing precision and clarity. Finding a balance between these extremes lets users shape results to their needs. It also affects tone and style based on context and goals.
FINE-TUNING TEMPERATURE FOR SPECIFIC LANGUAGE TASKS AND APPLICATIONS
Temperature plays a crucial role in shaping the responses of large-language models. This parameter lets users control the creativity and variability of the text token by token. A lower-temperature setting tends to produce more focused and deterministic outputs. It is best for tasks that need precision, like technical writing or data presentations. Readers get clear, concise information without unnecessary embellishment. Finding the right balance is key. Fine-tuning temperature lets practitioners shape the model behavior.They can create engaging dialogue or insightful academic papers. Larger models typically perform better when trying different parameters, often giving surprising results. They can greatly improve performance.
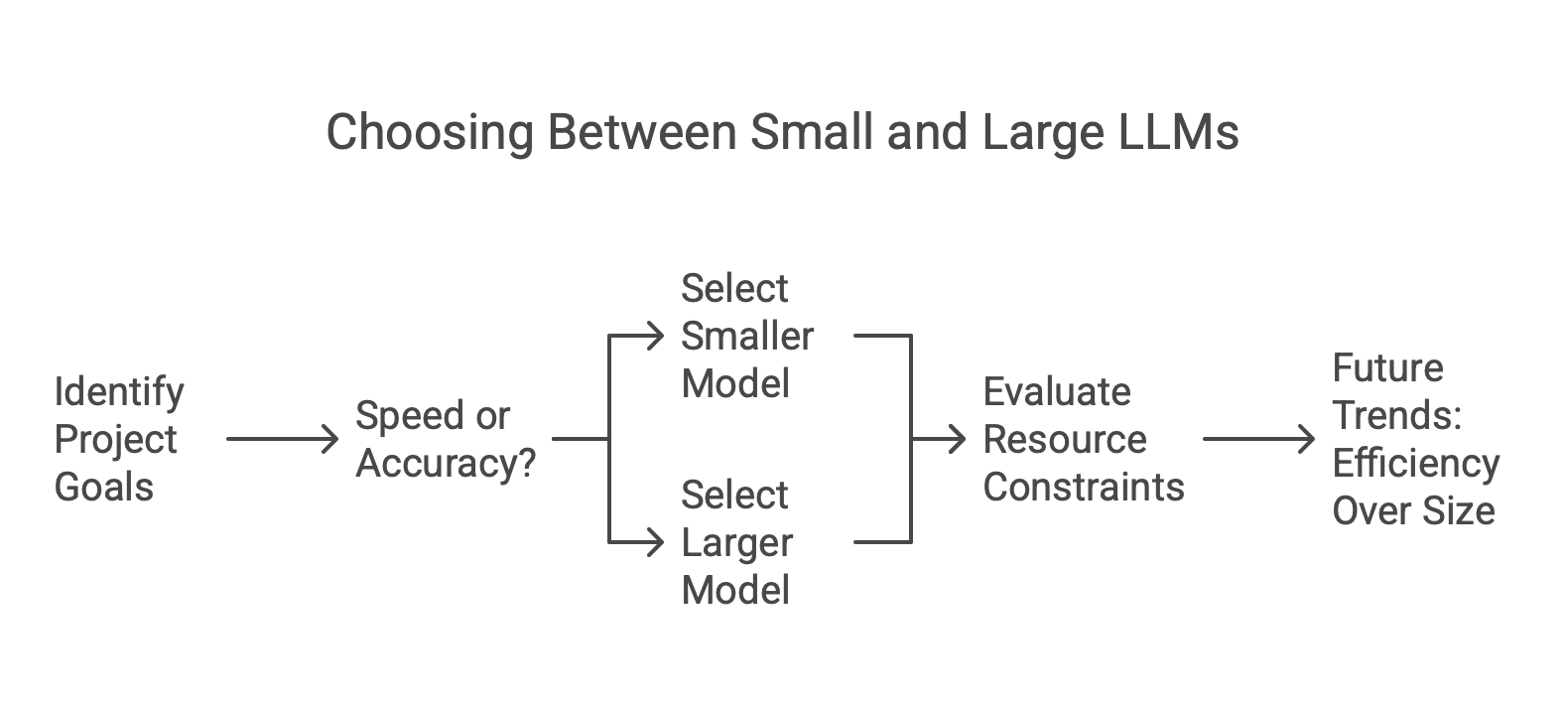
WHAT ARE THE KEY DIFFERENCES BETWEEN SMALLER AND LARGER LLM MODELS?
Smaller and larger LLMs exhibit distinct characteristics that influence their usability. Little models are often lightweight, making them suitable for deployment in resource-constrained environments. They must less computing power and can deliver faster responses. On bigger models have a more extensive parameter set. This expansion enhances their ability to generate nuanced text and understand complex context of llms. Their performance shines in tasks demanding high accuracy or creativity. Bigger isn't always better for every application. Little models may excel in cases where speed is key. Large LLMs might struggle with efficiency in real-time chats. They must too many resources. Choose small or large hinges based on the project's goals. Balance speed, accuracy, and resources.
COMPARING PERFORMANCE AND CAPABILITIES ACROSS MODEL SIZES
When comparing performance across different model scales, consider the context. Smaller-models often excel in tasks requiring quick responses and less computing power. Theyre ideal for applications where efficiency is key.
- Performance of Larger-Models: Bigger models usually perform better due to their improved understanding of language and ability to generate text more effectively.
- Advantages of Larger-scale Models:
- Their vast several parameters allows them to capture intricate patterns in data.
- They are highly versatile and flexible.
- Advantages of Compact Models: Compact models can be quickly tailored for specific tasks without requiring extensive retraining.
Organizations choose their LLMs based on a balance. It is between capability and adaptability. It must fit their needs and resources.
WHEN TO CHOOSE A SMALLER MODEL OVER A LARGER ONE
Selecting a smaller-model can be helpful in various scenarios. First, consider computing efficiency. Smaller-models need less power and memory. So, they are ideal for low-resource devices.
Speed is another crucial factor. For quick responses, like in mobile apps or real-time data analysis, a little model is better. It can provide faster results without the overhead of bigger models. Cost considerations also come into play. Training and maintaining large models often cost a lot for hardware and cloud services.
THE FUTURE OF LLM SCALING: WILL BIGGER ALWAYS BE BETTER?
As LLMs evolve, a question arises: will bigger always be better? Future developments may favor smarter architectural designs over sheer volume. Techniques like model distillation might allow smaller-models to excel. They could outperform larger, heavier ones while using fewer resources.
| Aspect | Scaling Up (Bigger Models) | Alternative Approaches |
|---|---|---|
| Performance | Generally improves with size, especially for complex tasks. | Specialized fine-tuning, retrieval-augmented generation (RAG). |
| Cost | Expensive computational and energy demands. | Smaller, more efficient models reduce cost. |
| Efficiency | Diminishing returns as models grow. | Focus on optimizing architectures and sparsity. |
| Accessibility | Limited to organizations with significant resources. | Democratization via smaller, open-source models. |
| Specialization | Large models are general-purpose but may lack domain expertise. | Smaller models fine-tuned for specific tasks. |
| Sustainability | Increasing environmental impact from massive models. | Energy-efficient designs and distributed systems. |
| Innovation Focus | Larger models test theoretical limits of scaling laws. | Focus shifts to hybrid approaches and multimodality. |
Real-world applications demand agility and adaptability. Smaller-LLMs can excel at special tasks. They lack the overhead of larger ones. Future advancements will likely focus on balancing capability and efficiency. This will change our view of the best model in different settings.
HOW DO LLM PARAMETERS IMPACT NATURAL LANGUAGE PROCESSING TASKS?
LLM-parameters play a crucial role in NLP tasks. These parameters affect a model's understanding of context, grammar, and meaning. Their number of tokens and quality matter.
OPTIMIZING PARAMETERS FOR SPECIFIC NLP APPLICATIONS
When it comes to improving parameters for specific NLP applications, context is key. Various tasks must different levels of model complexity and finesse. For instance, sentiment analysis might do better with fewer parameters. It would then give clear responses.
Conversely, bigger models with more nuanced parameters are often better. They can create more creative content. This allows the model to capture subtlety and depth in language.
Aligning parameter choices with task requirements can significantly improve outcomes. It's about finding the sweet spot where efficiency meets effectiveness. We want to improve user experiences across apps while managing resource use.
THE ROLE OF PARAMETERS IN GENERATING HUMAN-LIKE TEXT
Parameters are crucial for creating human like text in large-language models. They are the building blocks of a model's language skills. They determine how it understands and generates language.
Each parameter captures nuances of meaning, grammar, and context. As models learn from vast data sets, their parameters adapt. They show patterns in human language. As they refine the model, it will produce better sentences. They will be coherent and contextually relevant. This is particularly evident in tools like GitHub Copilot vs ChatGPT, where the former excels in code-specific tasks while the latter demonstrates versatility in generating human-like text across diverse contexts.
This makes interactions feel natural and intuitive. A well-tuned set of parameters can generate varied, creative responses that mimic humans. Subtle adjustments can lead to different tones or stylesbe it formal or casual.
BALANCING PARAMETER COUNT WITH TASK-SPECIFIC PERFORMANCE
It's vital to balance parameter count and performance in large-language models. This is key to their efficiency. Too many parameters can cause overfitting. A model then learns the training-data too well but struggles with new inputs.
Experimentation is key. Tuning the model for specific needs ensures the best results in different scenarios. Each application has unique demands. They affect the balance between size and performance.
WHAT ARE THE CHALLENGES IN OPTIMIZING LLM PARAMETERS?
Improving parameters in large-language models presents a unique set of challenges. One significant hurdle is balancing performance with computing constraints. As models become larger, they need more resources. This makes them less accessible to smaller organizations and individual developers. Another challenge lies in addressing biases inherent in the training-data. These biases can skew parameter learning. Ensuring fairness and objectivity becomes critical but complex to achieve. Efficient use of memory and processing power remains a persistent goal. Developers are exploring ways to boost LLM efficiency and cut resource use. But, it's tough to balance these goals in this fast-changing field.
BALANCING MODEL PERFORMANCE WITH COMPUTATIONAL CONSTRAINTS
Developing large language models is hard. It is a challenge to balance performance with limits on computation. As these models grow, so does their demand for resources. High-performance settings often must large processing power and memory. This can lead to increased costs and longer training times.
Not every organization has the infrastructure to support such needs. Developers must decide how many parameters to include, as this refers to the number of adjustable elements in the model. They must keep the model efficient. Striking this balance is essential for practical applications. Techniques like pruning or quantization can manage resource use.
They can do this without losing much performance. These methods let developers make lighter versions of existing models. They are now more accessible. The push for efficiency doesn't mean sacrificing quality. It means finding smarter ways to use technology, while knowing its limits.
ADDRESSING BIASES AND LIMITATIONS IN PARAMETER LEARNING
Biases in large language models are a pressing concern. These biases often arise from the data used during training. If the data set contains skewed representations, the model can reflect these inaccuracies. Addressing these limitations requires careful curation of training-data. A diverse and representative dataset helps mitigate inherent biases. Some biases may persist in a well-rounded data set. This is due to how parameters learn patterns. However, when applied to the best AI tools for coding, such as GitHub Copilot or ChatGPT, these models can still deliver highly accurate and context-aware assistance, provided their training data is rigorously vetted and balanced.
Regular audits of LLM outputs can reveal unexpected bias behavior. This ongoing evaluation is crucial for improving fairness and inclusivity in generated content, as models require continuous monitoring and refinement. Interdisciplinary teams can deepen understanding and find solutions in AI. They can address both technical and ethical challenges in its development.
THE ONGOING QUEST FOR MORE EFFICIENT PARAMETER UTILIZATION IN LLMS
The quest for better parameter use in LLM shows AI's fast pace. As researchers try to improve large language models, they face many challenges. Balancing model performance with computing constraints is paramount. Bigger models often deliver impressive results but come at significant resource costs.
The need for efficiency drives innovation in how parameters are utilized and managed. As technology advances, the focus will likely shift. It will be to create smarter algorithms. They should maximize performance and cut computing demands. This pursuit boosts LLM efficacy and broadens access to apps.
